Pipelining in psql (PostgreSQL 18)
What is pipelining in Postgres?
Pipelining is a client-side feature supported by the network protocol that basically consists of not waiting for the results of previously sent queries before sending the next. This increases the throughput in two ways:
-
The client, network and server can work in parallel. For instance, the network may transmit the results of the (N-1)th query while the server executes the Nth query and the client sends the (N+1)th query, all this at the same time.
-
The network is better utilized because successive queries can be grouped in the same network packets, resulting in less packets overall.
Pipelining is possible since version 7.4 (released in 2003), which introduced the extended query protocol. But it’s only since 2021, with PostgreSQL 14, that it can be used through libpq, the client-side C library. Since then, some libpq-based drivers like psycopg3 have started to support it.
With PostgreSQL 18, released last week, psql, the command line client
comes equipped with commands to use pipelining in SQL scripts, making it
even more accessible.
While this addition is not part of the highlighted features of that release,
it can provide huge gains in query throughput, as we’re going to see in a simple
test.
psql commands
The pipeline is started with \startpipeline, and in the most simple case, followed
by the SQL queries and ended with \endpipeline.
If intermediate results are needed, we can use \syncpipeline to force a
synchronisation point and \getresults to fetch all results up to that point.
Also, starting a pipeline creates an implicit transaction. If a query fails,
all the changes since the start (or before the last synchronization point) will
be rolled back.
If you know about the \; syntax to group several queries in the same request, there are similarities between this technique and pipelining: they’re both used to reduce server round-trips and have the same semantics with regard to transactions. In a way, pipelining is the evolution in the extended query protocol of what multi-statement queries (\; in psql) are in the simple query protocol.
Performance test
Let’s do a simple test where data from devices are imported
with INSERT ... ON CONFLICT queries. Same-device same-date does update the row,
otherwise it inserts a new row.
Note that if we wanted to unconditionally append all rows,
COPY would be preferable and pipelining not necessary, which is why
the more sophisticated insert-or-update is chosen for that test.
The following bash code imports the (random) data, with or without the pipelining depending on a parameter.
function import_data
{
local count=$1 # how many rows?
local pipeline=$2 # 1 or 0
local now_ts=$(date +%s)
(
echo 'PREPARE s AS insert into events(device, recorded_at, measure)
values($1, to_timestamp($2), $3) on conflict(device,recorded_at) do update set measure=excluded.measure;'
echo "BEGIN;"
[[ $pipeline = 1 ]] && echo "\\startpipeline"
for i in $(seq 1 $count)
do
device=$RANDOM
secs=$(($now_ts + $RANDOM*50))
measure=${RANDOM}"."${RANDOM}
echo "execute s($device, '$secs', $measure);"
done
[[ $pipeline = 1 ]] && echo "\\endpipeline"
echo "COMMIT;"
) | $psql -q -v ON_ERROR_STOP=1
}
Let’s try this with batches of 100, 1000, 5000, 10000, 50000, 100000 rows, with and without pipelining, and compare how fast these batches are processed.
Also, since the network speed matters a lot here, let’s try with three typical kinds of network connections:
- localhost (ping time ~ 0.04ms): client and server are on the same host.
- LAN (ping time ~ 1ms): client and server are separated only by an Ethernet 1GB/s switch.
- WAN (ping time ~ 4ms): the server is reached through a public Internet connection.
Finally, each case is run 5 times and we keep only the median time of the runs.
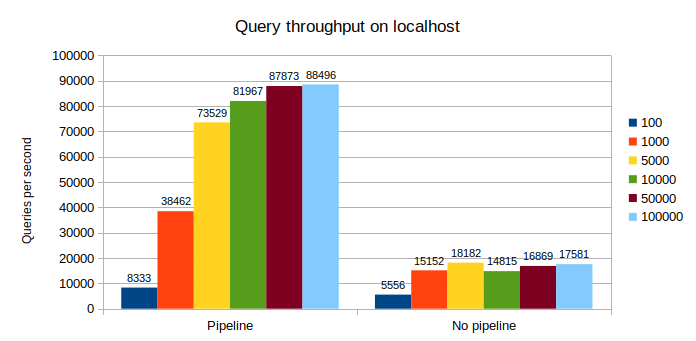
On the same host, the pipeline acceleration ranges from 1.5x for the smallest batch size, up to 5x.
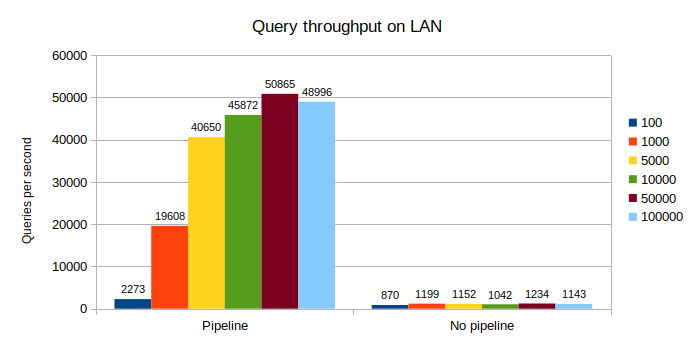
On a local network connection, the smallest batch size is accelerated by 2.6x, and it goes up to 42x with the bigger sizes.
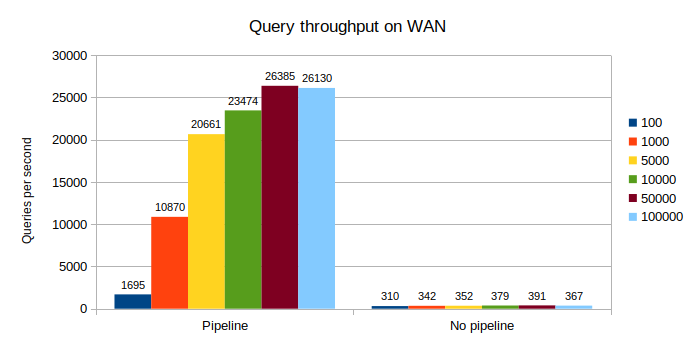
On the slowest network, it’s even more impressive. The acceleration is between 5.4x and 71x !
Conclusion
These accelerations show how under-utilized the network is when we send batches of small queries without pipelining: the network packets are like 50 seater buses that ride with only one passenger.
In our example, all we have to do to optimize on that front
is to add a pair of \startpipeline and \endpipeline.
That’s because our queries do not depend on the results of previous queries
of the same batch, except in the sense that if one fails, the entire batch fails.
Without pipelining, we could still optimize our test by adding many
rows to the VALUES clauses for each query instead of one row per
query. But it’s not easy to find the sweet spot for how many data rows
there needs to be per query, and large queries with thousands of parameters
are not the nicest to handle on the server side.
Also, if the client-side logic is more complicated, for instance
conditionally targeting several tables, running simple statements in
a pipeline while using row-by-row logic might be much easier.
The pipelining meta-commands were added in psql version 18, but they do not require PostgreSQL 18 on the server side. For those interested in this feature who can’t upgrade their server soon, you can still upgrade to the latest version of psql: it’s backward-compatible as much as possible.