Exposing more of ICU to PostgreSQL
Since version 10, Postgres can be configured with ICU,
the reference library for Unicode, to use its collations in COLLATE clauses.
To that end, ICU collations for most language/countries pairs
are automatically created at initdb time (they will be found in pg_catalog.pg_collation),
and others can be added later with CREATE COLLATION.
Beyond collation support, ICU provides other services focused on locale-aware and multilingual text processing, following Unicode recommendations.
Once our Postgres instances are linked with ICU (most are because the major packagers like Apt, Rpm, or the Edb Installer have opted to include it), why not try to benefit from all these services through SQL?
This is the goal of icu_ext,
a C extension providing SQL wrapper functions to ICU. As of now, it
brings about twenty functions allowing to inspect locales and
collations, identify text boundaries, compare and sort strings,
spoof-check strings, spell numbers, transliterate between scripts.
Before looking into compare and sort functions, let’s recall what the ICU integration already provides.
Benefits of ICU versus collations from the OS
-
Versioning:
pg_collation.collversionholds the version number of each collation when created, and if ever at runtime it doesn’t match the version ICU provides (typically following an upgrade), a warning is issued, urging the user to rebuild potentially affected indexes and register the new collation version in the catalog. -
Cross-OS consistency: the same ICU collation sorts identically across all operating systems, which is not the case with the C libraries. For instance,
lc_collateset to the sameen_US.UTF-8behaves differently on Linux and FreeBSD: pairs of strings as simple as0102and"0102"sort in opposite orders. -
Indexing speed: Postgres uses abbreviated keys when available (also called sort keys in ICU terminology), because they can really speed up indexing. But since the libc support for this feature (
strxfrm) has been found to be buggy in several operating systems, it’s only activated for ICU collations. -
Parameterized string comparisons: in libc, there’s typically a one-to-one mapping between locale and collation, like for instance
fr_CA.UTF-8compares strings with the linguistic rules of French as written in Canada, but without further customization or control. With ICU, collations accept a handful of parameters that offers possibilities beyond the language-country specification, as demonstrated in the online ICU Collation Demo, or Peter Eisentraut’s blog post “More robust collations with ICU support in PostgreSQL 10” announcing the feature last year, or in “What users can do with custom ICU collations in Postgres 10” (discussion in pgsql-hackers).
What Postgres can’t do yet with ICU collations
Unfortunately there is a problem preventing to use the advanced comparisons to their full potential: the current infrastructure in Postgres for text comparisons cannot handle strings being equal when they are not equivalent byte-for-byte. To enforce this constraint, when strings compare as equal with the linguistic comparison (strcoll-like), Postgres runs an strcmp tie-breaker on them, and discards the result of the ICU collator (or libc’s, for that matter) in favor of that bytewise comparison.
For instance, we might create this collation:
CREATE COLLATION "fr-ci" (
locale = 'fr-u-ks-level1', /* or 'fr@colStrength=primary' */
provider = 'icu'
);ks-level1 here means primary collation strength.
Be warned that this syntax with parameters as BCP-47 tags is silently ineffective
with older versions of ICU (53 or older). When unsure of the syntax,
you may pass it to icu_collation_attributes() to check
how ICU parses it, as shown a bit below in this post.
icu_version() also
Anyway, there are five levels of strength, the primary level considering only the base characters so that case and accent differences are ignored.
The point with the strcmp tie-breaker is that the following equality will not be satisfied, contrary to what we might expect if we were not aware of it:
=# SELECT 'Eté' = 'été' COLLATE "fr-ci" as equality;
equality
----------
fHopefully we’ll get the ability to make these case-insensitive-and-more collations work seamlessly in a future version of Postgres, but in the meantime, it’s possible to somehow circumvent this problem with functions from icu_ext. Let’s see how.
Comparing strings with functions from icu_ext
The main function is:
icu_compare(string1 text, string2 text [, collator text]).
It returns the result of ucol_strcoll[UTF8](), comparing
string1 and string2 with collator as the ICU collation.
It’s a signed integer, negative if string1 < string2, zero if string =
string2, and positive if string1 > string2.
When the 3rd argument collator is present, it’s not the name of a db
collation declared with CREATE COLLATION, but the value that would
be passed as its locale or lc_collate parameter if we had to
instantiate that collation. In other words, it’s a locale ID
from the point of view of ICU independantly of Postgres
(yes, ICU uses the term “ID” to denote a string argument that is
more less a built-up string)
When the collator argument is missing, it is the collation associated
to string1 and string2 that is used for the comparison.
It must be an ICU collation and it must be the same for the two
arguments or the function will error out. This form
with a single argument is significantly faster due to Postgres keeping its
collations “open” (in the sense of ucol_open()/ucol_close()) for the
duration of the session, whereas the other form with the
explicit collator argument does open and close the ICU collation
at each call.
To get back at the previous example, this time we can witness the equality of strings under the regime of case & accent insensitiveness:
=# SELECT icu_compare('Eté', 'été', 'fr-u-ks-level1');
icu_compare
-------------
0Case-sensitive, accent-insensitive comparisons are also possible:
=# SELECT icu_compare('abécédaire','abecedaire','fr-u-ks-level1-kc'),
icu_compare('Abécédaire','abecedaire','fr-u-ks-level1-kc');
icu_compare | icu_compare
-------------+-------------
0 | 1With an implicit Postgres collation:
=# CREATE COLLATION mycoll (locale='fr-u-ks-level1', provider='icu');
CREATE COLLATION
=# CREATE TABLE books (id int, title text COLLATE "mycoll");
CREATE TABLE
=# insert into books values(1, 'C''est l''été');
INSERT 0 1
=# select id,title from books where icu_compare (title, 'c''est l''ete') = 0; id | title
----+-------------
1 | C'est l'été
Handling combining diacritics
In Unicode, accented letters may be written in composed form in decomposed form, the latter being with an unaccented letter followed by the accent character from the Combining Diacritical Marks Block.
The two decomposed forms, NFD or NFKD
are infrequently used in UTF-8 documents, but they’re perfectly valid and
accepted by Postgres. Semantically, 'à' is supposedly equivalent to
E'a\u0300'. At least, ICU collators seem to see them as equal, even
under the strictest comparison level:
=# CREATE COLLATION "en-identic" (provider='icu', locale='en-u-ks-identic');
CREATE COLLATION
=# SELECT icu_compare('à', E'a\u0300', 'en-u-ks-identic'),
'à' = E'a\u0300' COLLATE "en-identic" AS "equal_op";
icu_compare | equal_op
-------------+----------
0 | f(again, the Postgres equal operator disagrees because of the tie-breaker. The point of using functions as an alternative is precisely to bypass it).
Besides, combining characters are not only about accents, since some of them achieve text effects such as strikethrough or underlines. Let’s see an example from within psql, as displayed on a gnome terminal. The query in the screenshot below takes the literal ‘Hello’, inserts combining marks from U+0330 to U+0338 after every character, returning the result and comparing it with the original string with primary and secondary comparison strengths.
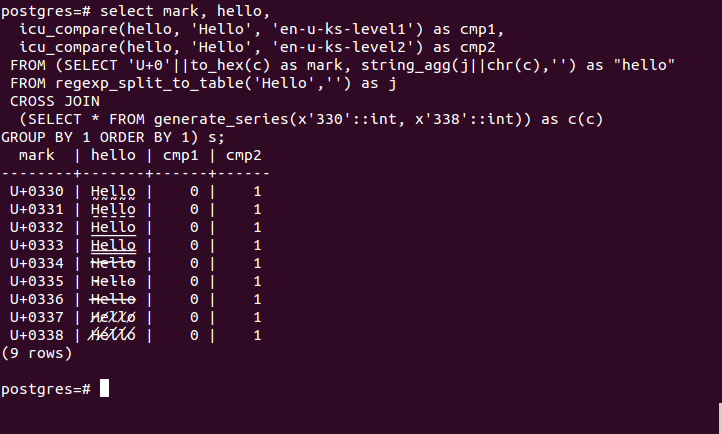
In general, ICU functions seem to take combining marks into account when it makes sense, whereas non-ICU functions in Postgres (with regular expressions, for instances) consider a combining mark as a codepoint like any other.
Sorting and grouping
The ORDER BY and GROUP BY clauses are not designed to work with functions comparing two arguments, but they do work with single-argument functions that transform their input into something else. To sort or group results according to all ICU advanced linguistic rules, icu_ext exposes a function that converts a single string into a sort key:
function icu_sort_key(string text [, icu_collation text]) returns bytea
This is the same sort key as what is used implicitly by Postgres to create
indexes involving ICU collations.
The promise of the sort key is that, if icu_compare(s1, s2, collator) returns X, then
the (faster) bytewise comparison between icu_sort_key(s1, collator) and
icu_sort_key(s2, collator) returns X too.
The ICU documentation warns that computing a sort key is slow, much slower than doing a single comparison with the same collation. But in the context of ORDER BY in queries an to the extent of my tests, they seem to do quite well.
In fact when looking at the performance of ORDER BY field COLLATE "icu-coll" versus
ORDER BY icu_sort_key(field, 'collation'), most of the difference appears
to be caused by icu_sort_key having to parse the collation specification
for each call, especially for complex specifications.
Just like for icu_compare(), to benefit from Postgres caching collator
objects for the duration of the session, it’s recommended to use the
single-argument form, which relies on the collation of the argument,
for instance, with our “fr-ci” collation declared previously:
=# SELECT icu_sort_key ('Eté' COLLATE "fr-ci")
Still on performance, here’s a comparison of EXPLAIN ANALYZE for
sorting 6.6 million short words (13 characters on average) with
icu_sort_key versus ORDER BY directly on the field:
ml=# explain analyze select wordtext from words order by icu_sort_key(wordtext collate "frci");
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=371515.53..1015224.24 rows=5517118 width=46) (actual time=3289.004..5845.748 rows=6621524 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=370515.51..377411.90 rows=2758559 width=46) (actual time=3274.132..3581.209 rows=2207175 loops=3)
Sort Key: (icu_sort_key((wordtext)::text))
Sort Method: quicksort Memory: 229038kB
-> Parallel Seq Scan on words (cost=0.00..75411.99 rows=2758559 width=46) (actual time=13.361..1877.528 rows=2207175 loops=3)
Planning time: 0.105 ms
Execution time: 6165.902 msml=# explain analyze select wordtext from words order by wordtext collate "frci";
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=553195.63..1196904.34 rows=5517118 width=132) (actual time=2490.891..6231.454 rows=6621524 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=552195.61..559092.01 rows=2758559 width=132) (actual time=2485.254..2784.511 rows=2207175 loops=3)
Sort Key: wordtext COLLATE frci
Sort Method: quicksort Memory: 231433kB
-> Parallel Seq Scan on words (cost=0.00..68515.59 rows=2758559 width=132) (actual time=0.023..275.519 rows=2207175 loops=3)
Planning time: 0.701 ms
Execution time: 6565.687 msWe can see here that there’s no notable performance degradation
when calling icu_sort_key explicitly. In fact in this example it’s
slightly faster for some reason.
GROUP BY or DISTINCT ON can use sort keys, too:
=# select count(distinct title) from books;
count
-------
2402
=# select count(distinct icu_sort_key(title)) from books;
count
-------
2360Using sort keys in indexes
The ordered position or unicity of a piece of text under a certain collation is equivalent to
the ordered position or unicity of its binary sort key computed with that collation.
So it’s possible to create an index, including to enforce a unique constraint,
on icu_sort_key(column) or icu_sort_key(column, collator) rather than just column
to work around the “non-binary-equal is not equal” rule for
ICU collations.
Using the previous example of with the books table, we could do:
=# CREATE INDEX ON books (icu_sort_key(title));
and then getting it used for exact matches with
=# SELECT title FROM books WHERE
icu_sort_key(title) = icu_sort_key('cortege' collate "mycoll");
title
---------
Cortège
CORTÈGE
Just to check that our index is effectively used:
=# explain select title from books where icu_sort_key(title)=icu_sort_key('cortege' collate "mycoll");
QUERY PLAN
-------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=4.30..10.64 rows=2 width=29)
Recheck Cond: (icu_sort_key(title) = '\x2d454b4f313531'::bytea)
-> Bitmap Index Scan on books_icu_sort_key_idx (cost=0.00..4.29 rows=2 width=0)
Index Cond: (icu_sort_key(title) = '\x2d454b4f313531'::bytea)
Inspecting collations
As mentioned above, when refering to a collation, old and new versions of ICU don’t necessarily understand the same syntax and tags, and they also tend to ignore anything they can’t parse instead of reporting an error.
To make sure that a collation is correctly spelled or does what you
expect, the output of icu_collation_attributes() can be examined.
This function takes a collation name as input, collects its
properties, and returns them as a set of (attribute, value) couples with
the display name (probably the most important attribute),
plus tags such as kn/kb/kk/ka/ks/kf/kc, and finally the version of the collation.
Example:
postgres=# select * from icu_collation_attributes('en-u-ks-identic');
attribute | value
-------------+---------------------------------
displayname | anglais (colstrength=identical)
kn | false
kb | false
kk | false
ka | noignore
ks | identic
kf | false
kc | false
version | 153.80
(9 rows)
-- We got a french output for displayname, but
-- it could be, say, in Japanese
postgres=# select icu_set_default_locale('ja');
icu_set_default_locale
------------------------
ja
(1 row)
-- Note the change in displayname
postgres=# select * from icu_collation_attributes('en-u-ks-identic');
attribute | value
-------------+------------------------------
displayname | 英語 (colstrength=identical)
kn | false
kb | false
kk | false
ka | noignore
ks | identic
kf | false
kc | false
version | 153.80
(9 rows)Other functions
Besides comparisons and sort keys, icu_ext brings SQL wrappers to
a bunch of other ICU functionalities
(see the README.md
in the sources for at least one example per function):
-
icu_{character,words,line,sentence}_boundaries
Break down a string into its constituents and return them as sets of text. Basically it’a better version ofregexp_split_to_table(string, regexp)that use linguistic rules recommended by the Unicode standard instead of regexp-based separators. -
icu_char_name
Output the Unicode name of any character out of the 130K+ of the charset. -
icu_confusable_strings_check and icu_spoof_check
Tell if pairs of strings appear similar-looking and if strings has characters that might be meant to deceive a reader. -
icu_locales_list
List all locales with languages and countries in localized versions. Incidentally, that gives country and languages names translated into many languages (Useicu_set_default_locale()to switch languages). -
icu_number_spellout
Spell out numbers in different locales. -
icu_transforms_list and icu_transform
Powerful text transformations and transliterations (conversions between scripts). There are more than 600 basic transforms listed by icu_transforms_list and they can be combined with filters. There is an online demo for this service.
Hopefully other functions will be added into icu_ext, as time permits, and more examples on how to use the existing ones. In the meantime, feel free to submit issues or pull requests on github if some functions don’t do what you expect, or if you’d like specific ICU services being exposed and with what interface, or exposed differently than what icu_ext does at the moment…