Looking at the new built-in collation provider in PostgreSQL 17
Among the novelties of PostgreSQL 17, recently released in beta, there’s a built-in UTF-8 locale and collation with binary string comparisons. In this post, let’s see why it’s interesting, how to use it and how it performs.
A third collation provider
Before version 17, we can choose between two providers: the libc library, which comes with the operating system, and the optional ICU library. v17 adds a third provider for collations implemented in Postgres itself.
The announce describes it as:
PostgreSQL 17 includes a built-in collation provider that provides similar sorting semantics to the C collation except with UTF-8 encoding rather than SQL_ASCII. This new collation is guaranteed to be immutable, ensuring that the return values of your sorts won’t change regardless of what system your PostgreSQL installation runs on.
There are two built-in collations, both for UTF-8.
SELECT
collnamespace::regnamespace,
collname,
colllocale,
pg_encoding_to_char(collencoding) as encoding
FROM pg_collation WHERE collprovider='b'; -- 'b' = 'built-in'
collnamespace | collname | colllocale | encoding
---------------+-----------+------------+----------
pg_catalog | ucs_basic | C | UTF8
pg_catalog | pg_c_utf8 | C.UTF-8 | UTF8
ucs_basic already existed in previous versions with the “libc” provider
and was identical to the "C" collation in UTF8 databases. It’s the same
in version 17, that is:
- for string comparisons, it uses the byte order, without any linguistic rule.
- for character classification (i.e. knowing if such or such character is a letter, a digit, a lower case or upper case letter…), it answers according to an internal table for any code point below 127 (the ASCII characters), and for the rest, it answers “No” to any of these questions.
So although it’s technically possible to use ucs_basic or "C" in UTF-8
databases, it’s not adequate for non-english contents.
The new C.UTF-8 built-in locale and its pg_c_utf8 collation address
this, giving correct results
for all code points of the Unicode repertoire at the time of the release
(almost 150000 as of Unicode 15.1), and thus
allowing proper case conversions and regular expressions with all alphabets.
Now, it’s also the case for the Unicode collations provided by libc and ICU, but the point is that the new locale/collation provides this combination of features in the same locale:
- fast, immutable binary sorts (no ICU locale does that)
- OS independence (no libc locale provides that except “C”)
- Full Unicode character classification (“C” is missing it).
Let’s illustrate this with a Venn diagram:

Note that ICU’s independence on the OS does not mean that OS upgrades are transparent with ICU. OS distributions tend to come with the latest version of the ICU library at the time when the distribution is made, so upgrading an OS generally means upgrading ICU at the same time, unless you compile it yourself. OS independence with regard to ICU means that when using the same version of ICU on different operating systems, collations behave identically across these systems.
How to use it
To use the new collation by default when creating an instance or a database,
we select it with the locale name C.UTF8 and the provider "builtin"
(beware not to confuse it with the C.UTF-8 or C.utf8 locales of libc).
At the instance level:
initdb --locale-provider=builtin --locale=C.UTF8 -D /usr/local/pgsql/data
In that case, all databases created in that instance will use that new locale by default.
Otherwise, on an already existing instance initialized with the libc or ICU providers, to create a specific database with the new built-in locale, we should do it like this:
CREATE DATABASE test locale_provider='builtin' builtin_locale='C.UTF8' template='template0';
If you wonder why we need to force template0 (instead of the default template1),
it’s because the server assumes that we might have added localized data into template1
that might be incompatible with the locale of our new database.
template0 contains non-modifiable base catalogs that are locale-agnostic,
making it a safe choice,
whereas template1 is template0 plus whatever additions a DBA has made.
Finally, from inside a database that doesn’t use that new locale by default,
we can add COLLATE pg_c_utf8 clauses at the SQL level on columns
or expressions, for instance:
CREATE INDEX idx ON tablename using btree(columnname COLLATE pg_c_utf8);
Then such an index will be considered by the query planner for queries like, for instance:
SELECT * FROM tablename WHERE columnname = 'some-value' COLLATE pg_c_utf8;
Indexing and search performance
Bytewise comparisons uses less CPU than linguistic comparisons. Let’s illustrate this on some data of the Internet Movie Database:
name_basics is a table with about 13 million rows.
The primaryName column holds the names of people who worked on movies,
with about 10 million distinct values. It’s a good example to sort and search into with
different collations.
\d name_basics
Table "public.name_basics"
Column | Type | Collation | Nullable | Default
-------------------+----------------------+-----------+----------+---------
sn_soundex | character varying(5) | | |
deathYear | integer | | |
primaryProfession | text | | |
nconst | integer | | |
primaryName | text | | |
birthYear | integer | | |
s_soundex | character varying(5) | | |
ns_soundex | character varying(5) | | |
knownForTitles | text | | |
Indexes:
"idx" btree ("primaryName")
Let’s see how much time it takes to build the btree index on “primaryName” on databases created with different locales, on a Linux Debian 12 system (GNU libc 2.36, ICU 72).
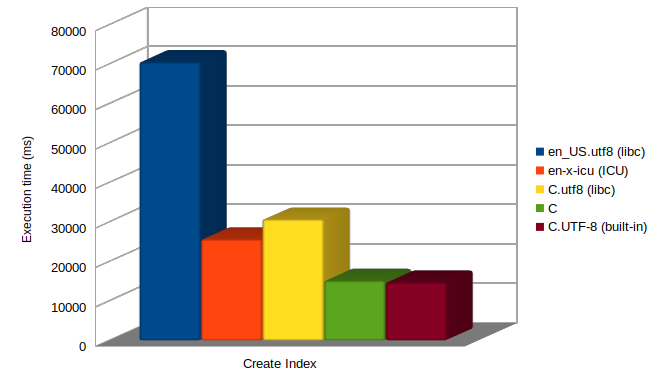
How to interpret these differences
- libc’s
en_US.utf8is the slowest: it does linguistic comparisons without abbreviated keys 1 - ICU’s
en-x-icudoes linguistic comparisons, but with the abbreviated keys optimisation. - libc’s
C.utf8does faster binary comparisons, but Postgres does not “know it”, so instead of using an optimized fast path, it calls the slower generic function. Cand the newC.UTF-8locales are optimized for the fastest execution and perform similarly well.
After indexing the column, let’s see how the queries compare in execution time across databases. For that test, we use pg_bench with a query searching for 1000 values at the time:
SELECT count(*) FROM name_basics WHERE "primaryName" IN
(
...<list of 1000 names previously randomly choosen from the table >...
)
The plan for this query is an Index Only Scan, matching 6572 rows.
The median execution times are as follows:
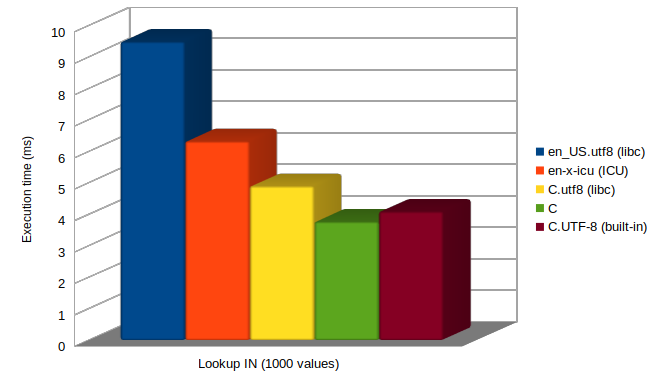
The differences are roughly like in the index creation, except that
the gap between en_US.utf8 and en-x-icu is larger when indexing.
My theory is that it is because of the abbreviated keys optimization that
is disabled with en_US.utf8, versus enabled with ICU collations.
Abbreviated keys are used on sorts, but not on lookups.
A recent post on depesz’s blog (How much speed you’re leaving at the table if you use default locale?) also shows a benchmark comparing these collations, but using
COLLATE clauses instead of defining the locale at the database level, as I do
for the numbers reported above.
Depesz notes that the binary comparisons perform better, as expected,
but also that the built-in pg_c_utf8 collation performs significantly
worse than the "C" collation, and wonders why. The answer comes as a follow-up
by Jeff Davis on the pgsql-hackers list: Speed up collation cache. In short, comparisons with
non-default collations currently imply cache lookups that could be better optimized.
Hopefully this will be improved soon, but still, it’s good to remember
that the database locale should be prefered over COLLATE clauses for
faster results.
Sorting of results
The main drawback of the binary-sorting collations is that they don’t sort the “human way”.
For instance, let’s say we want to output all primaryName starting with “Adèle” or “Adele”, in a sorted list. We’re going to make a query like this:
SELECT DISTINCT "primaryName" FROM name_basics
WHERE "primaryName" ~ '^Adèle' OR "primaryName" ~ '^Adele'
ORDER BY "primaryName" ;
With a binary sort order, we’re getting this output:
primaryName
------------------------------
Adele
Adele & The French StarKids
Adele Aalto
Adele Abbott
Adele Abinante
[...]
Adèle de Fontbrune
Adèle de Mesnard
Adèle de la Fuente
Adèle van Biljon
Adèle-Elise Prévost
(1342 rows)
The “Adele” are grouped together in the first part of the list, and
the “Adèle” are in a second part.
That’s because the code point of the è letter (U+00E8) is greater than the code point of
the e letter (U+00065).
When using a linguistic collation like fr_FR.utf8, the output is better:
primaryName
------------------------------
Adele
Adèle
Adele Aalto
Adele Abbott
Adele Abinante
Adele Abou Ali
Adele Aburrow
Adele Adams
Adele Adderley
Adele Addison
Adele Addo
Adele Adeshayo
Adele Adkins
Adèle Ado
[...]
Adele Zeiner
Adele Zin
Adele Zoppis
Adèle Zouane
Adele Zupicic
(1342 rows)
In this list, the accented and non-accented e letters are together, and it’s
the last name that mostly drives the order. It’s clearly what we (humans) prefer to see.
To get this sort in a binary-sorting database, a COLLATE clause with a linguist
collation should be added to the ORDER BY. It could be
ORDER BY "primaryName" COLLATE "en_US.utf8"(or some other libc collation). It works only if that collation does exist in the database, which depends on the OS and the installation, so it’s not portable. It also forces a specific language/country, which might not be what an application wants.ORDER BY "primaryName" COLLATE "en-x-icu"with an ICU collation. The advantage is that every Postgres instance with ICU enabled will have this collation, so it’s almost portable. However this again forces a specific language.ORDER BY "primaryName" COLLATE "unicode", that exists since Postgres 16. It calls for the “root” collation that is designed to work well across all languages. With Postgres 15 and older, we can use the less easy to memorize"und-x-icu".
In practice, modern client applications are likely to be equipped with sort capabilities that make them not rely on database sorts. For instance a Javascript modern app might use Navigator.language and Intl.Collator to sort according to the browser’s language. It will be more natural for most developers to get Javascript to sort the list than to find a database collation matching the browser’s language and inject it into the SQL query. If a list of results might be too large to be handled by the browser, then sure, the database-side sort is back in the game.
The other benefit of binary-sorted text indexes
Besides being faster, binary-sorted indexes supports left-anchored searches directly.
In the previous query, if we have only a linguistic-sorted index on "primaryName",
we’re getting a slow sequential scan:
EXPLAIN ANALYZE select distinct "primaryName" from name_basics
where "primaryName" ~ '^Adèle' or "primaryName" ~ '^Adele'
order by "primaryName";
Unique (cost=243279.95..243541.75 rows=2174 width=14) (actual time=4354.978..4356.406 rows=1342 loops=1)
-> Gather Merge (cost=243279.95..243536.32 rows=2174 width=14) (actual time=4354.978..4356.212 rows=1398 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Unique (cost=242279.92..242285.36 rows=1087 width=14) (actual time=4346.459..4346.578 rows=466 loops=3)
-> Sort (cost=242279.92..242282.64 rows=1087 width=14) (actual time=4346.453..4346.482 rows=487 loops=3)
Sort Key: "primaryName"
Sort Method: quicksort Memory: 25kB
Worker 0: Sort Method: quicksort Memory: 25kB
Worker 1: Sort Method: quicksort Memory: 25kB
-> Parallel Seq Scan on name_basics (cost=0.00..242225.11 rows=1087 width=14) (actual time=9.747..4345.114 rows=487 loops=3)
Filter: (("primaryName" ~ '^Adèle'::text) OR ("primaryName" ~ '^Adele'::text))
Rows Removed by Filter: 4345599
Planning Time: 0.186 ms
Execution Time: 4356.494 ms
The advice given by the documentation to accelerate this is to create a second index with varchar_pattern_ops:
The operator classes text_pattern_ops, varchar_pattern_ops, and bpchar_pattern_ops support B-tree indexes on the types text, varchar, and char respectively. The difference from the default operator classes is that the values are compared strictly character by character rather than according to the locale-specific collation rules. This makes these operator classes suitable for use by queries involving pattern matching expressions (LIKE or POSIX regular expressions) when the database does not use the standard “C” locale. As an example, you might index a varchar column like this:
CREATE INDEX test_index ON test_table (col varchar_pattern_ops);
The good news is that the new C.UTF-8 built-in locale and pg_c_utf8 collation benefit
from the same advantage as the standard “C” locale: they can be used directly for left-anchored search, as shown with the execution plan with such an index:
Unique (cost=162.45..175.49 rows=2607 width=14) (actual time=30.616..31.048 rows=1342 loops=1)
-> Sort (cost=162.45..168.97 rows=2608 width=14) (actual time=30.612..30.699 rows=1461 loops=1)
Sort Key: "primaryName"
Sort Method: quicksort Memory: 49kB
-> Bitmap Heap Scan on name_basics (cost=10.44..14.46 rows=2608 width=14) (actual time=0.571..26.297 rows=1461 loops=1)
Recheck Cond: (("primaryName" ~ '^Adèle'::text) OR ("primaryName" ~ '^Adele'::text))
Filter: (("primaryName" ~ '^Adèle'::text) OR ("primaryName" ~ '^Adele'::text))
Heap Blocks: exact=1451
-> BitmapOr (cost=10.44..10.44 rows=1 width=0) (actual time=0.356..0.357 rows=0 loops=1)
-> Bitmap Index Scan on idx (cost=0.00..4.57 rows=1 width=0) (actual time=0.126..0.127 rows=268 loops=1)
Index Cond: (("primaryName" >= 'Adèle'::text) AND ("primaryName" < 'Adèlf'::text))
-> Bitmap Index Scan on idx (cost=0.00..4.57 rows=1 width=0) (actual time=0.227..0.227 rows=1193 loops=1)
Index Cond: (("primaryName" >= 'Adele'::text) AND ("primaryName" < 'Adelf'::text))
Planning Time: 0.473 ms
Execution Time: 31.132 ms
Conclusion
Let’s summarize the main collation characteristics in this table:
| “C” or ucs_basic |
libc collations other than “C” |
ICU collations | pg_c_utf8 | |
|---|---|---|---|---|
| Portability between OSes? | ✅ Yes | ❌ No | ✅ Yes | ✅ Yes |
| Bytewise comparisons? | ✅ Yes | ❓ Some | ❌ No | ✅ Yes |
| Abbreviated keys? 1 | - | ❌ No | ✅ Yes | - |
| Transparent OS updates? 2 | ✅ Yes | ❌ No | ❌ No | ✅ Yes |
| Unicode classification? | ❌ No | ✅ Yes | ✅ Yes | ✅ Yes |
| Linguistic sort? | ❌ No | ✅ Yes | ✅ Yes | ❌ No |
| Advanced comparisons? 3 | ❌ No | ❌ No | ✅ Yes | ❌ No |
The new built-in provider in Postgres 17 provides a fast, portable,
easier-to-upgrade C.UTF-8 locale / pg_c_utf8 collation. Although it does not
have the more advanced capabilities we get with the ICU provider,
it’s likely to be a good default locale for Unicode databases.
For more on the subject, I recommend watching this excellent presentation on YouTube: Collations from A to Z (PGConf.dev 2024) by Jeremy Schneider and Jeff Davis. Jeremy first presents quite a list of unintuitive facts and paint points related to collations (with a few references to this blog I noticed 🤓 ) and then Jeff, who is the author of this Postgres 17 new feature, details what can be done with existing collations and how the new locale fits into that context.
Notes
-
Abbreviated keys are binary representations of strings to accelerate sorts with linguistic collations. See Peter Geoghegan’s post Abbreviated keys: exploiting locality to improve PostgreSQL's text sort performance (from 2015) explaining that feature. In theory, libc collations could use them too, but the implementations have been found buggy and therefore unsafe to use for indexing. ↩ ↩2
-
Strictly speaking, OS updates are not transparent when they imply an Unicode upgrade. Even with binary sorts solving the main issue, the addition of code points in Unicode can theorically change the results of check constraints involving regular expressions, case conversion or normalization rules. ↩
-
Advanced comparisons means all features allowed by ICU non-deterministic collations, among which case-insensitive and accent-insensitive comparisons. ↩